Exploring News Archive Data with Pandas
4 comments

The above image was made by @amberjyang with Midjourney using the prompt 'a computer panda working on a computer in a world of coding numbers.'
Background
Last year, I wrote a news recommendation algorithm for WantToKnow.info. You can read about the project here and test out the recommendations by clicking on any article title in our archive. The recommendations are based on something called TF-IDF vector cosine similarity, which is to say the mathematical relationships between news stories.
More recently, I was inspired to expand the underlying tech to vector search for situations when keyword search isn't optimal. So I wrote a proof-of-concept vector search app using Pyscript. It takes any detailed question or description of any conspiracy-related topic as input and outputs a list of the 20 most relevant news article summaries from our archive. Now I'm looking at making the app more useful, which means including more features in the Pandas dataframe it's built on.
Playing with Pandas
WantToKnow's news database is fairly clean to begin with. From my exploration, it looks like more than 99% of the entries are valid and complete. Its 12,970 valid entries have all been manually curated over the last 20 years, making this the highest quality archive of conspiracy news that I'm aware of.
Two data features that I wanted to make available for my app are category and publication information. The category information is stored in 3 tables, so I had to join those together correctly and store the category values in a convenient way. Publisher information was much trickier as news sources haven't always been attributed in standardized ways in our database. New York Times, The New York Times, and The New York Times Blog all appear as separate sources, so I had to write code to condense such duplicate entries into single publisher names.
A few years ago, I created a dictionary called mediacondense to use as a key for standardizing publisher info. Over the last couple of days, I've expanded and cleaned up the mediacondense dictionary. This has been a tedious manual process of spotting duplicate variations of media sources and then updating the dictionary, plus running various find/replace commands to account for all variations.
That work is already paying off. Right away I was able to chart publication data in a way that had previously been impossible. In the future, my mediacondense key could be used to standardize the publication data in our main database, laying the groundwork for making articles on our site searchable by news source. Below are the publication and category charts I made, as well as the code used to make these charts.
Here's what news sources WantToKnow.info uses
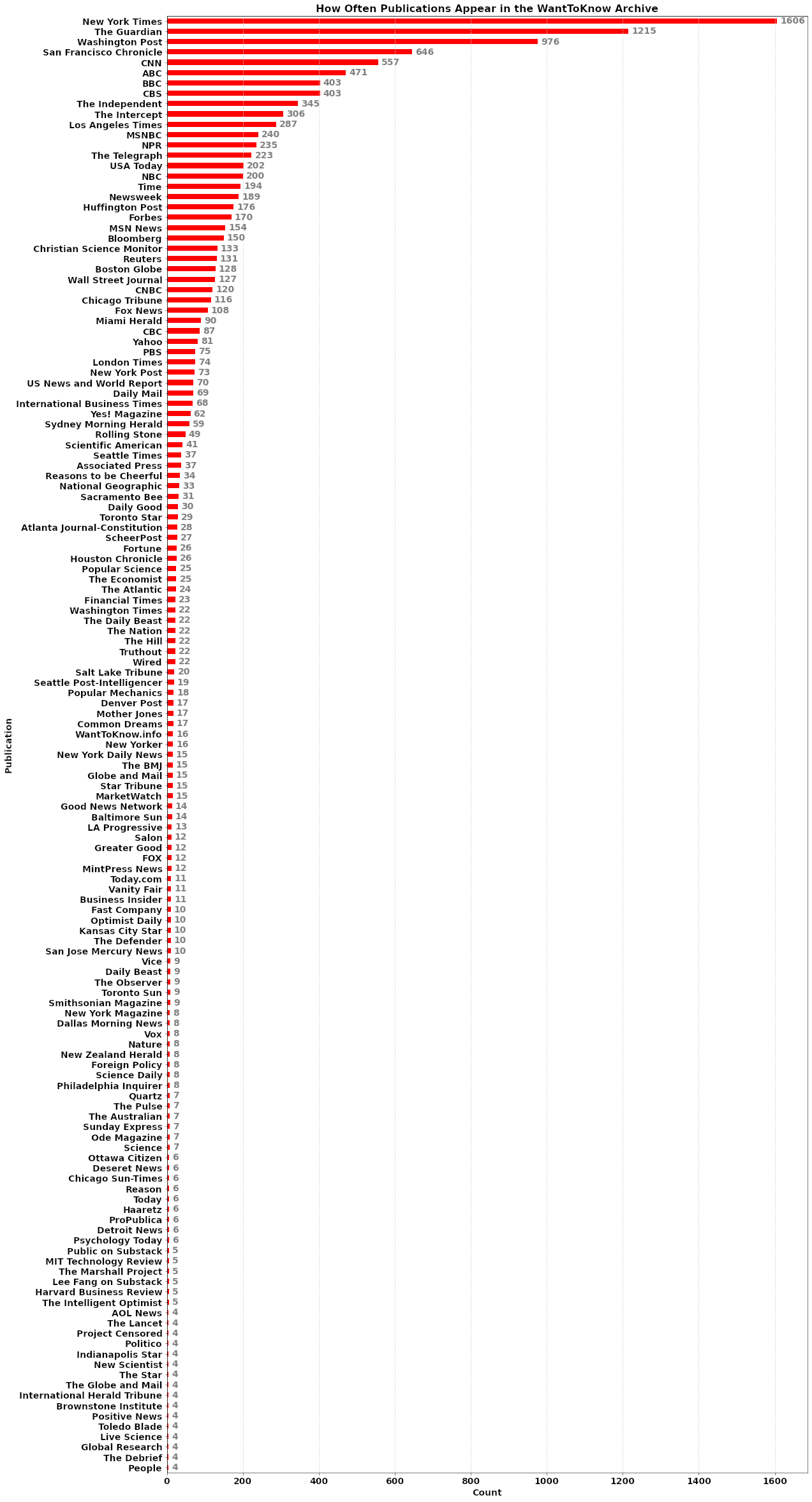
Here's how many news stories fall into each category
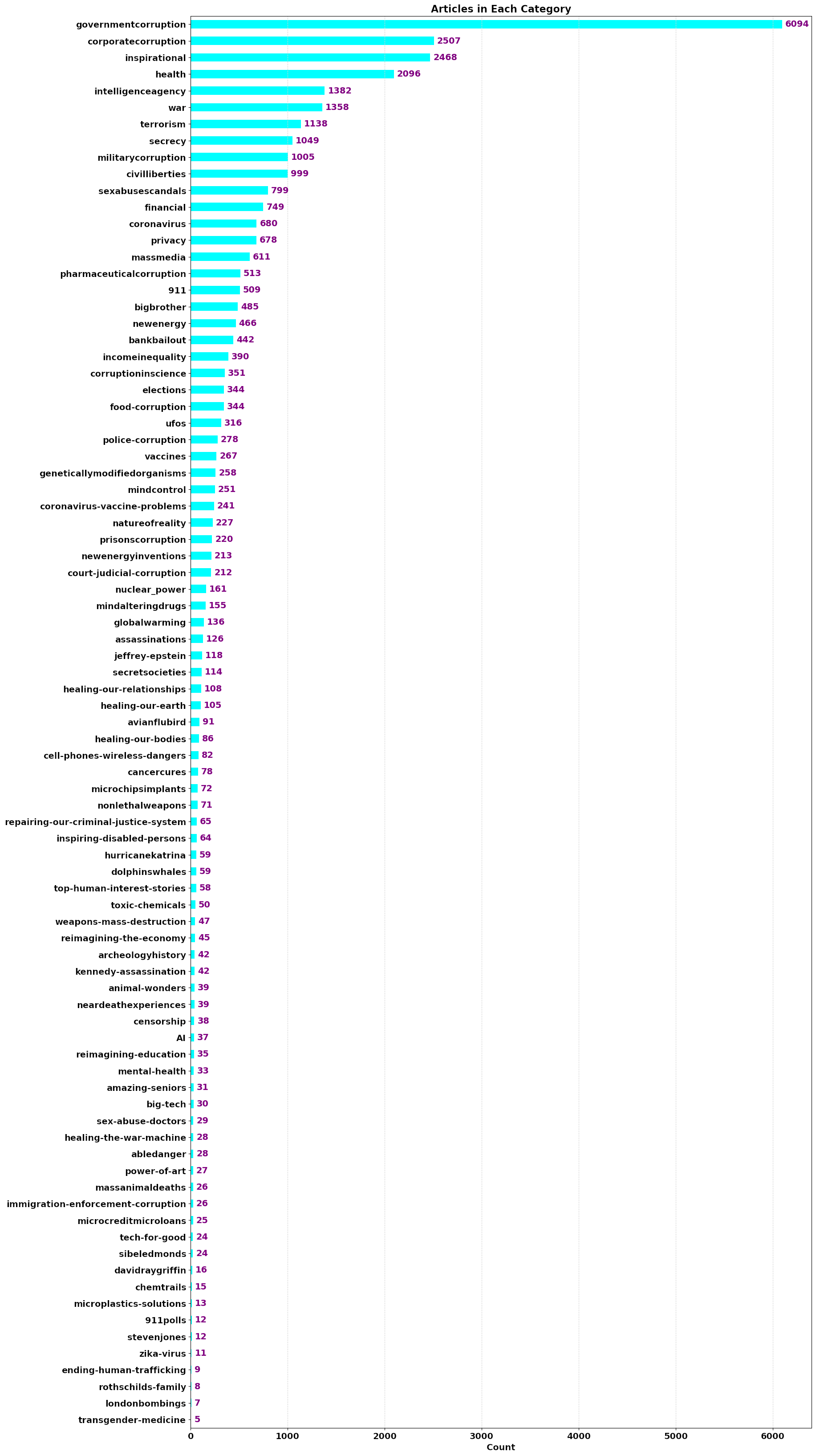
Here's the code I used
import pandas as pd
import numpy as np
import os
import re
import matplotlib.pyplot as plt
from collections import Counter
#read in category tables data
dftemp_A = pd.read_csv("C:/datasources/CategoryArticle.csv", sep='|')
dftemp_B = pd.read_csv("C:/datasources/Category.csv", sep='|', usecols=['cid','url'])
#cast to str for merge
dftemp_A['cid'] = dftemp_A['cid'].astype(str)
dftemp_B['cid'] = dftemp_B['cid'].astype(str)
# Merge the two dataframes on the 'cid' column
merged_df = pd.merge(dftemp_A, dftemp_B, on='cid')
# Group the merged dataframe by 'ArticleId' and aggregate the 'url' values into a list
dftemp_C = merged_df.groupby('ArticleId')['url'].apply(list).reset_index()
dftemp_C.rename(columns={"url": "tags"}, inplace=True)
# Save the grouped dataframe to the alltags.csv file
#dftemp_C.to_csv('C:/datasources/alltags.csv', index=False, encoding='utf-8')
#transform dataframe to dictionary
v = dftemp_C.groupby('ArticleId')['tags'].apply(lambda t: list(t)).to_dict()
#read in raw articles table data
dftemp_DB = pd.read_csv("C:\\datasources\\ArticleScrubbed.csv", sep='|', usecols=['ArticleId','Title','PublicationDate','Publication','Links','Description','Priority','url'])
#make some unique wtk urls
makeurl = dftemp_DB['url'].astype(str)
dftemp_DB['wtkURL'] = "https://www.wanttoknow.info/a-" + makeurl
#make tags column and populate with dictionary v
dftemp_DB['tags'] = dftemp_DB['ArticleId'].map(v)
#remove rows without valid Title or tags values
dftemp_DB = dftemp_DB[dftemp_DB['Description'].notna()]
dftemp_DB = dftemp_DB[dftemp_DB['tags'].notna()]
dftemp_DB = dftemp_DB[dftemp_DB['Publication'].notna()]
#clean up tags
dftemp_DB['tags'] = dftemp_DB['tags'].astype(str).apply(lambda v: v.replace('\'', ''))
dftemp_DB['tags'] = dftemp_DB['tags'].astype(str).apply(lambda v: v.replace('[[', '['))
dftemp_DB['tags'] = dftemp_DB['tags'].astype(str).apply(lambda v: v.replace(']]', ']'))
#remove markup from publications
dftemp_DB['Publication'] = dftemp_DB['Publication'].str.replace('<i>', '')
dftemp_DB['Publication'] = dftemp_DB['Publication'].str.replace('</i>', '')
dftemp_DB['Publication'] = dftemp_DB['Publication'].str.replace('<em>', '')
dftemp_DB['Publication'] = dftemp_DB['Publication'].str.replace('<', '')
dftemp_DB['Publication'] = dftemp_DB['Publication'].str.replace('>', '')
#begin cleanup of media sources
dftemp_DB['Publication'], dftemp_DB['pub2'] = dftemp_DB['Publication'].str.split('/', 1).str
dftemp_DB['Publication'], dftemp_DB['pubdetail'] = dftemp_DB['Publication'].str.split('(', 1).str
dftemp_DB['pubdetail'] = dftemp_DB['pubdetail'].astype(str).apply(lambda u: u.strip(')'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].str.strip()
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda u: u.strip('"'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('\'',''))
#drop extra columns
dftemp_DB.drop(columns=['pub2', 'pubdetail'], inplace=True)
#one-off translations. Move sources with more than two variations to mediacondense
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Seattle times', 'Seattle Times'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Scientific American Blog', 'Scientific American'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('The Sacramento Bee', 'Sacramento Bee'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Mother Jones Magazine', 'Mother Jones'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Sydney Mountain Herald', 'Sydney Morning Herald'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('The Nation magazine', 'The Nation'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Chicago Sun-Times News Group', 'Chicago Sun-Times'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Wired magazine', 'Wired'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('The New Yorker magazine', 'The New Yorker'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Fortune magazine', 'Fortune'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('The Atlantic Monthly', 'The Atlantic'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Tikkun Magazine - March', 'Tikkun Magazine'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('The Daily Mail', 'Daily Mail'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('U.S. Right to Know', 'US Right to Know'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Wired Magazine', 'Wired'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Minneapolis Star-Tribune', 'Star Tribune'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('CNBC News', 'CNBC'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('Minneapolis Star Tribune', 'Star Tribune'))
dftemp_DB['Publication'] = dftemp_DB['Publication'].astype(str).apply(lambda r: r.replace('The New Yorker', 'New Yorker'))
#mediacondense is a list of dictionaries for when there are more than 2 variations of a media source
mediacondense = []
abc = ['ABC News Australia', 'ABC News blog', 'ABC6', 'abcnews.com', 'WCPO - Cincinnatis ABC Affiliate', 'ABC News', 'ABC News blogs', 'ABC News Blog', 'ABC News Good Morning America', 'ABC New', 'ABC News Nightline', 'ABC15', 'ABC News 20', 'abc4.com', 'ABC Action News', 'ABCs Arizona Affiliate','WXYZ - Detroits ABC News Affiliate']
mcat1 = "ABC"
m1 = dict.fromkeys(abc, mcat1)
mediacondense.append(m1)
ode = ['Ode Magazine, June 2005 Issue', 'Ode Magazine, July 2005 Issue', 'Ode magazine']
mcat2 = "Ode Magazine"
m2 = dict.fromkeys(ode, mcat2)
mediacondense.append(m2)
nbc = ['NBC Milwaukee Affiliate', 'NBC Philadelphia', 'NBC Today', 'NBC New York', 'NBC Right Now', 'NBC Chicago', 'NBC Miami', 'NBC Washington', 'NBC Los Angeles', 'NBC Oklahoma City', 'NBC News']
mcat3 = "NBC"
m3 = dict.fromkeys(nbc, mcat3)
mediacondense.append(m3)
vfr = ['Vanity Fair August 2006 Issue', 'Vanity Fair September 2005 Issue', 'Vanity Fair magazine']
mcat4 = "Vanity Fair"
m4 = dict.fromkeys(vfr, mcat4)
mediacondense.append(m4)
nyt = ['The New York Times', 'New York Times Blog', 'New York Times blog']
mcat5 = "New York Times"
m5 = dict.fromkeys(nyt, mcat5)
mediacondense.append(m5)
unw = ['U.S. News and World Report', 'U.S. News & World Report blog', 'U.S. News & World Report', 'U.S. News & World Report blog', 'US News & World Report magazine', 'US News & World Report']
mcat6 = "US News and World Report"
m6 = dict.fromkeys(unw, mcat6)
mediacondense.append(m6)
nwk = ['Newsweek magazine', 'Newsweek blog', 'Newsweek Magazine', 'Newsweek magazine blog']
mcat7 = "Newsweek"
m7 = dict.fromkeys(nwk, mcat7)
mediacondense.append(m7)
bbc = ['BBC Radio', 'BBC News blog', 'BBC Blogs', 'BBC News']
mcat8 = "BBC"
m8 = dict.fromkeys(bbc, mcat8)
mediacondense.append(m8)
fop = ['Foreign Policy Magazine May', 'Foreign Policy Journal']
mcat9 = "Foreign Policy"
m9 = dict.fromkeys(fop, mcat9)
mediacondense.append(m9)
wap = ['Washington Post blog', 'washingtonpost.com', 'Washingon Post', 'Washginton Post', 'The Washington Post']
mcat10 = "Washington Post"
m10 = dict.fromkeys(wap, mcat10)
mediacondense.append(m10)
tlg = ['The Telegraph blogs', 'Daily Telegraph', 'Telegraph']
mcat11 = "The Telegraph"
m11 = dict.fromkeys(tlg, mcat11)
mediacondense.append(m11)
nsa = ['U.S. National Security Agency Website', 'National Security Agency Website', 'NSA Technical Journal, Vol. XI', 'National Security Agency Website, NSA Technical Journal, Vol. XI']
mcat12 = "NSA Website"
m12 = dict.fromkeys(nsa, mcat12)
mediacondense.append(m12)
msn = ['MSN Money', 'MSN of Australia', 'MSN Canada', 'MSN']
mcat13 = "MSN News"
m13 = dict.fromkeys(msn, mcat13)
mediacondense.append(m13)
tim = ['Time magazine', 'Time Magazine', 'TIME Magazine', 'Time Magazine blog']
mcat14 = "Time"
m14 = dict.fromkeys(tim, mcat14)
mediacondense.append(m14)
psc = ['Popular Science - March 2007 Issue', 'Popular Science Magazine', 'Popular Science magazine']
mcat15 = "Popular Science"
m15 = dict.fromkeys(psc, mcat15)
mediacondense.append(m15)
cnn = ['CNN blog', 'CNN Money', 'CNN International', 'CNN World', 'CNN The Situation Room', 'CNN Lou Dobbs Tonight', 'CNN Video Clip', 'CNN Larry King Live', 'CNN News']
mcat16 = "CNN"
m16 = dict.fromkeys(cnn, mcat16)
mediacondense.append(m16)
cbs = ['CBS Las Vegas Affiliate', 'CBS Cleveland', 'CBS4-TV', 'CBS Philly', 'CBS News', 'KCBS', 'CBS Atlanta', 'CBS Affiliate KUTV', 'CBS News Chicago, Associated Press', 'CBS News, Sacramento Affiliate', 'WCBS News - New York CBS Affiliate', 'CBS News 60 Minutes', 'CBS News 60 Minutes Overtime', 'CBS Los Angeles', 'CBS 60 Minutes', 'CBS News blog', 'CBS News, Stockton Affiliate']
mcat17 = "CBS"
m17 = dict.fromkeys(cbs, mcat17)
mediacondense.append(m17)
yho = ['Yahoo! News', 'Yahoo!', 'Yahoo! Finance', 'Yahoo! News Australia', 'Yahoo News', 'Yahoo Finance']
mcat18 = "Yahoo"
m18 = dict.fromkeys(yho, mcat18)
mediacondense.append(m18)
wsj = ['The Wall Street Journal', 'Wall Street Journal blog', 'Full Page Ad in Wall Street Journal', 'Wall Street Journal Article by Former FBI Director Louis Freeh', 'Wall Street Journal Blog']
mcat19 = "Wall Street Journal"
m19 = dict.fromkeys(wsj, mcat19)
mediacondense.append(m19)
fox = ['Fox News Chicago', 'WJBK Fox 2', 'Fox News video clip', 'FOX News', 'Fox 19', 'Fox News Affiliate']
mcat20 = "FOX"
m20 = dict.fromkeys(fox, mcat20)
mediacondense.append(m20)
icp = ['The Intercept With Glenn Greenwald', 'The Intercept with Glenn Greenwald']
mcat21 = "The Intercept"
m21 = dict.fromkeys(icp, mcat21)
mediacondense.append(m21)
lat = ['Los Angeles Times blog', 'The Los Angeles Times', 'LA Times']
mcat22 = "Los Angeles Times"
m22 = dict.fromkeys(lat, mcat22)
mediacondense.append(m22)
pbs = ['PBS Nova Program', 'PBS Frontline', 'PBS, CBS, Fox compilation', 'PBS News', 'PBS Bill Moyers Journal', 'PBS Newshour', 'PBS Blog']
mcat23 = "PBS"
m23 = dict.fromkeys(pbs, mcat23)
mediacondense.append(m23)
ecn = ['The Economist blog', 'The Economist Magazine', 'The Economist magazine']
mcat24 = "The Economist"
m24 = dict.fromkeys(ecn, mcat24)
mediacondense.append(m24)
npr = ['NPR All Things Considered', 'National Public Radio', 'NPR News', 'NPR blog', 'NPR Blog', 'Minnesota Public Radio']
mcat25 = "NPR"
m25 = dict.fromkeys(npr, mcat25)
mediacondense.append(m25)
sfc = ['The San Francisco Chronicle', 'San Francisco Chronicle SFs leading newspaper)']
mcat26 = "San Francisco Chronicle"
m26 = dict.fromkeys(sfc, mcat26)
mediacondense.append(m26)
cbc = ['Canadian Broadcasting Corporation', 'CBC News', 'CBC News [Canadas Public Broadcasting System]']
mcat27 = "CBC"
m27 = dict.fromkeys(cbc, mcat27)
mediacondense.append(m27)
frb = ['Forbes Magazine', 'Forbes blog', 'Forbes India Magazine', 'Forbes magazine', 'Forbes.com', 'Forbes.com blog', 'Forbes India Magazine']
mcat28 = "Forbes"
m28 = dict.fromkeys(frb, mcat28)
mediacondense.append(m28)
rst = ['Rolling Stone blog', 'Rolling Stone magazine']
mcat29 = "Rolling Stone"
m29 = dict.fromkeys(rst, mcat29)
mediacondense.append(m29)
grd = ['A Guardian blog', 'The Guardian blog', 'Guardian', 'The Guardian']
mcat30 = "The Guardian"
m30 = dict.fromkeys(grd, mcat30)
mediacondense.append(m30)
ngc = ['NationalGeographic.com', 'National Geographic October 2004 Issue', 'National Geographic News', 'NationalGeographic.com blog']
mcat31 = "National Geographic"
m31 = dict.fromkeys(ngc, mcat31)
mediacondense.append(m31)
mbc = ['MSNBC News', 'MSNBC Today', 'MSNBC: Keith Olbermann blog', 'MSNBC The Rachel Maddow Show']
mcat32 = "MSNBC"
m32 = dict.fromkeys(mbc, mcat32)
mediacondense.append(m32)
rut = ['Reuters News Agency', 'Reuters News', 'Reuters Health', 'Reuters blog']
mcat33 = "Reuters"
m33 = dict.fromkeys(rut, mcat33)
mediacondense.append(m33)
blb = ['Bloomberg News Service', 'Businessweek', 'BloombergBusinessWeek', 'BloombergBusinessweek', 'BusinessWeek magazine', 'BusinessWeek', 'BusinessWeek Magazine', 'Bloomberg Businessweek', 'Bloomberg News']
mcat34 = "Bloomberg"
m34 = dict.fromkeys(blb, mcat34)
mediacondense.append(m34)
sdt = ['Times of London', 'The Times', 'Sunday Times']
mcat35 = "London Times"
m35 = dict.fromkeys(sdt, mcat35)
mediacondense.append(m35)
ind = ['Independent', 'The The The The The The The The Independent', 'The The The The The The The Independent']
mcat36 = "The Independent"
m36 = dict.fromkeys(ind, mcat36)
mediacondense.append(m36)
#the list of dictionaries is then turned into a new little dataframe
key = []
val = []
for i in mediacondense:
for k,v in i.items():
key.append(k)
val.append(v)
mediakeys = pd.DataFrame({'asis': key, 'clean': val})
#replacement values are mapped from new dataframe to complete main dataframe
#mediakeys.set_index('asis', inplace=True)
#mediakeys.to_csv("C:\\datasources\\mediakeys.csv", sep='|', index=True, encoding='utf-8')
# Creating a dictionary from the 'asis' and 'clean' columns
replace_dict = pd.Series(mediakeys['clean'].values, index=mediakeys['asis']).to_dict()
# Using map to update the 'Publication' column
dftemp_DB['Publication'] = dftemp_DB['Publication'].map(replace_dict).fillna(dftemp_DB['Publication'])
# Merging dftemp_DB with mediakeys on Publication column and asis column
dftemp_DB = dftemp_DB.merge(mediakeys, how='left', left_on='Publication', right_on='asis')
# Updating the Publication column with clean values
dftemp_DB['Publication'] = dftemp_DB['clean'].combine_first(dftemp_DB['Publication'])
# Dropping unnecessary columns
dftemp_DB.drop(columns=['asis', 'clean'], inplace=True)
# Calculating the value counts for the 'Publication' column
publication_counts = dftemp_DB['Publication'].value_counts()
# Filtering the counts to only include those greater than 4 and sorting in descending order
filtered_counts = publication_counts[publication_counts > 3].sort_values(ascending=False)
# Plotting the horizontal bar chart in descending order
plt.figure(figsize=(18, 42))
ax = filtered_counts.sort_values(ascending=True).plot(kind='barh', color='red', edgecolor='none')
# Increasing the bar thickness and label size
ax.bar_label(ax.containers[0], label_type='edge', padding=5, fontsize=14, color='gray', weight='bold')
plt.title('How Often Publications Appear in the WantToKnow Archive', fontsize=16, weight='bold')
plt.xlabel('Count', fontsize=14, weight='bold')
plt.ylabel('Publication', fontsize=14, weight='bold')
plt.xticks(fontsize=14, fontweight='bold')
plt.yticks(fontsize=14, fontweight='bold')
# Adding a light gray grid
plt.grid(axis='x', color='lightgray', linestyle='--', linewidth=0.7)
plt.show()
# Convert tags column to lists of strings
dftemp_DB['tags'] = dftemp_DB['tags'].str[1:-1].str.split(', ')
# Flatten the list of lists and filter out tags with less than 2 characters
all_tags = [tag.strip().strip("'") for sublist in dftemp_DB['tags'] for tag in sublist if len(tag.strip().strip("'")) >= 2]
# Count the occurrences of each tag
tag_counts = Counter(all_tags)
# Convert the tag counts to a DataFrame and sort
tag_counts_df = pd.DataFrame.from_dict(tag_counts, orient='index', columns=['Count']).sort_values(by='Count', ascending=False)
# Plotting the horizontal bar chart
fig, ax = plt.subplots(figsize=(18, 42), dpi=100) # Adjusting DPI to ensure proper size
tag_counts_df.sort_values(by='Count', ascending=True).plot(kind='barh', color='cyan', edgecolor='none', ax=ax, legend=False)
# Adding the counts next to the bars
ax.bar_label(ax.containers[0], label_type='edge', padding=5, fontsize=14, color='purple', weight='bold')
# Setting titles and labels
plt.title('Articles in Each Category', fontsize=16, weight='bold')
plt.xlabel('Count', fontsize=14, weight='bold')
#plt.ylabel('Category', fontsize=14, weight='bold')
plt.xticks(fontsize=14, fontweight='bold')
plt.yticks(fontsize=14, fontweight='bold')
# Adding a light gray grid
plt.grid(axis='x', color='lightgray', linestyle='--', linewidth=0.7)
# Save the figure as a .png file
#plt.savefig('C:/datasources/tag_count_barh.png', dpi=300, bbox_inches='tight')
# Displaying the plot
plt.show()
Next steps
My thinking is to make the charts above available in the app at the push of a button. If the underlying dataframe is updated, the charts being computed would be updated too. Of course, the data these charts communicate is low hanging fruit. Creating date range selection for the search may be a next step. But soon enough, I'll be diving into the OpenAI API to see if I can produce summary briefs of query results with the click of a button.
Eventually, I'd like to see WantToKnow implement search by publisher/publisher group. Getting there would take time, but it's pretty straightforward.
- Standardize publisher names in the database using the mediacondense key I generated.
- Change the admin interface where we enter article data, so that publishers are selected from a list instead of being typed in. It should be easy to add a new publisher to this list.
- This finite list of publishers could be used as the basis for integrating publisher data in search options, in the same way as category data is currently integrated.
Throughout this process, I've been experimenting with gpt-4o. It's been great for quickly producing matplotlib commands. The AI is great, but it has also led me astray. Code it generated corrupted the category data in a weird way, dicing up words and messing up results. The culprit turned out to be a heroic one-liner that never fully made sense to me. So I replaced it with more basic instructions and everything worked out okay. And I'm totally loving getting to know the strengths and weaknesses of gpt-4o.
Read Free Mind Gazette on Substack
Read my novels:
- Small Gods of Time Travel is available as a web book on IPFS and as a 41 piece Tezos NFT collection on Objkt.
- The Paradise Anomaly is available in print via Blurb and for Kindle on Amazon.
- Psychic Avalanche is available in print via Blurb and for Kindle on Amazon.
- One Man Embassy is available in print via Blurb and for Kindle on Amazon.
- Flying Saucer Shenanigans is available in print via Blurb and for Kindle on Amazon.
- Rainbow Lullaby is available in print via Blurb and for Kindle on Amazon.
- The Ostermann Method is available in print via Blurb and for Kindle on Amazon.
- Blue Dragon Mississippi is available in print via Blurb and for Kindle on Amazon.
See my NFTs:
- Small Gods of Time Travel is a 41 piece Tezos NFT collection on Objkt that goes with my book by the same name.
- History and the Machine is a 20 piece Tezos NFT collection on Objkt based on my series of oil paintings of interesting people from history.
- Artifacts of Mind Control is a 15 piece Tezos NFT collection on Objkt based on declassified CIA documents from the MKULTRA program.
Comments